Lesson 1
What is RAG
Before we understand RAG, let’s look at the limitation of a large language model.
Limitation of a large language model

Limitation 1: Limited Knowledge
Imagine you ask Cluade - When is the next Brazil match?
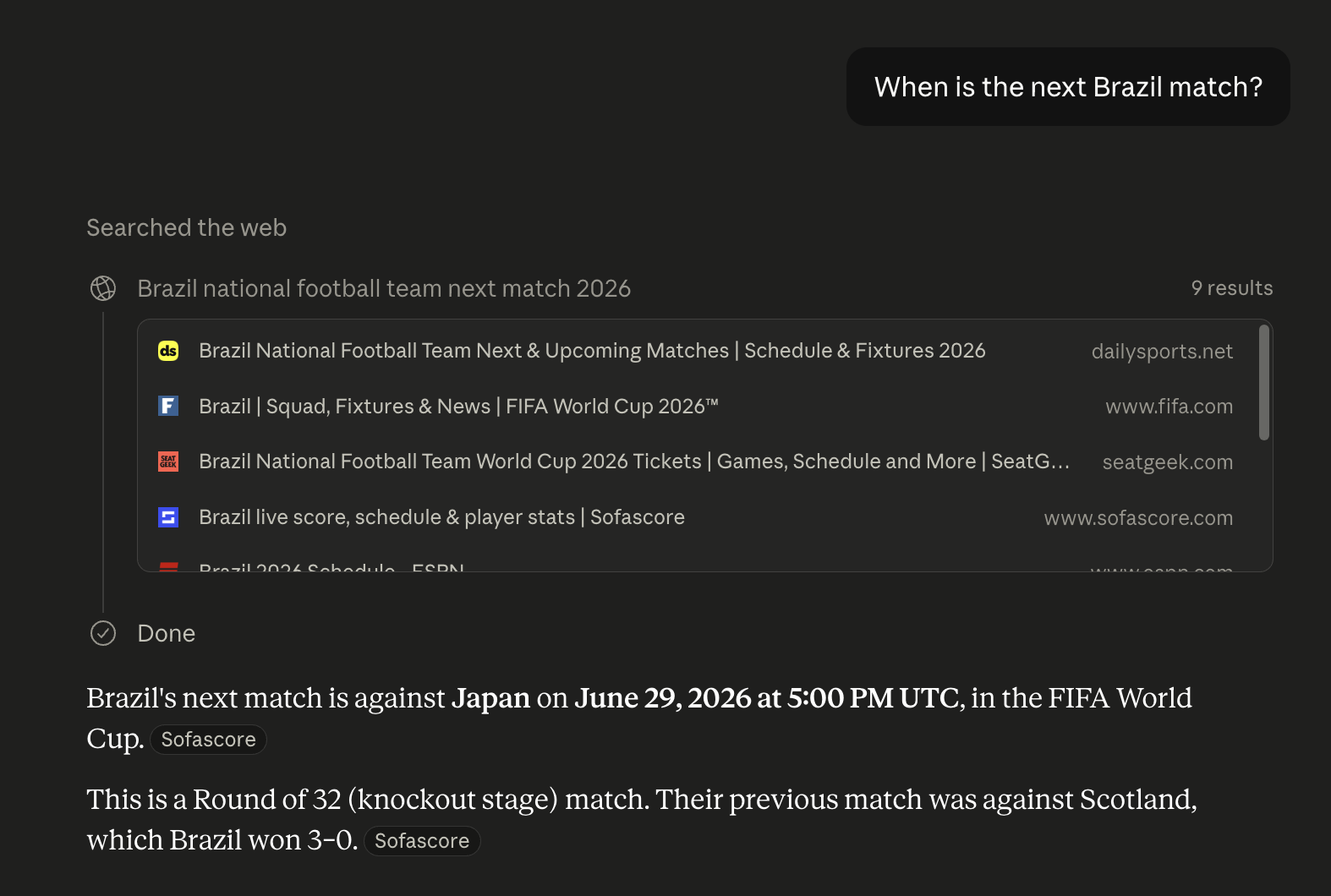
It cannot answer the above question without web search. An LLM only knows what it learned during training.
If something happened after its training cutoff, it has no idea unless it's connected to external information.
For example:
- Latest news
- Stock prices
- Today's weather
- New product releases
Without retrieval, the model cannot reliably answer these questions.
Limitation 2: No Knowledge of Your Private Data
Let’s say you ask Claude - What is the HR policy of Meta? It can’t answer it - because the model has never seen Meta’s private documents.

Limitation 3: Hallucinations
Sometimes LLMs sound extremely confident...
...while being completely wrong.
This phenomenon is called a hallucination.
Because the model doesn't know the answer, it tries to generate something that looks correct.
With RAG, the model is grounded in real documents, making hallucinations much less likely.
Limitation 4: Expensive Retraining
Suppose your company's policies change every week.
Should you retrain a billion-parameter model every week?
Of course not.
Training or fine-tuning large models is expensive and time-consuming.
Instead, simply update your documents.
RAG automatically retrieves the latest version whenever someone asks a question.
What is RAG?
RAG stands for Retrieval-Augmented Generation.
In simple words, RAG is a technique that allows an AI model to retrieve relevant information from an external knowledge source before generating an answer.
Instead of relying only on what it learned during training, the model first searches for relevant documents, then uses those documents as additional context while generating its response.
Think of it like an open-book exam.
A normal LLM answers questions only from memory.
A RAG-powered LLM is allowed to quickly open a textbook, find the relevant pages, and then answer your question based on that information.
How does Retrieval-Augmented Generation work?
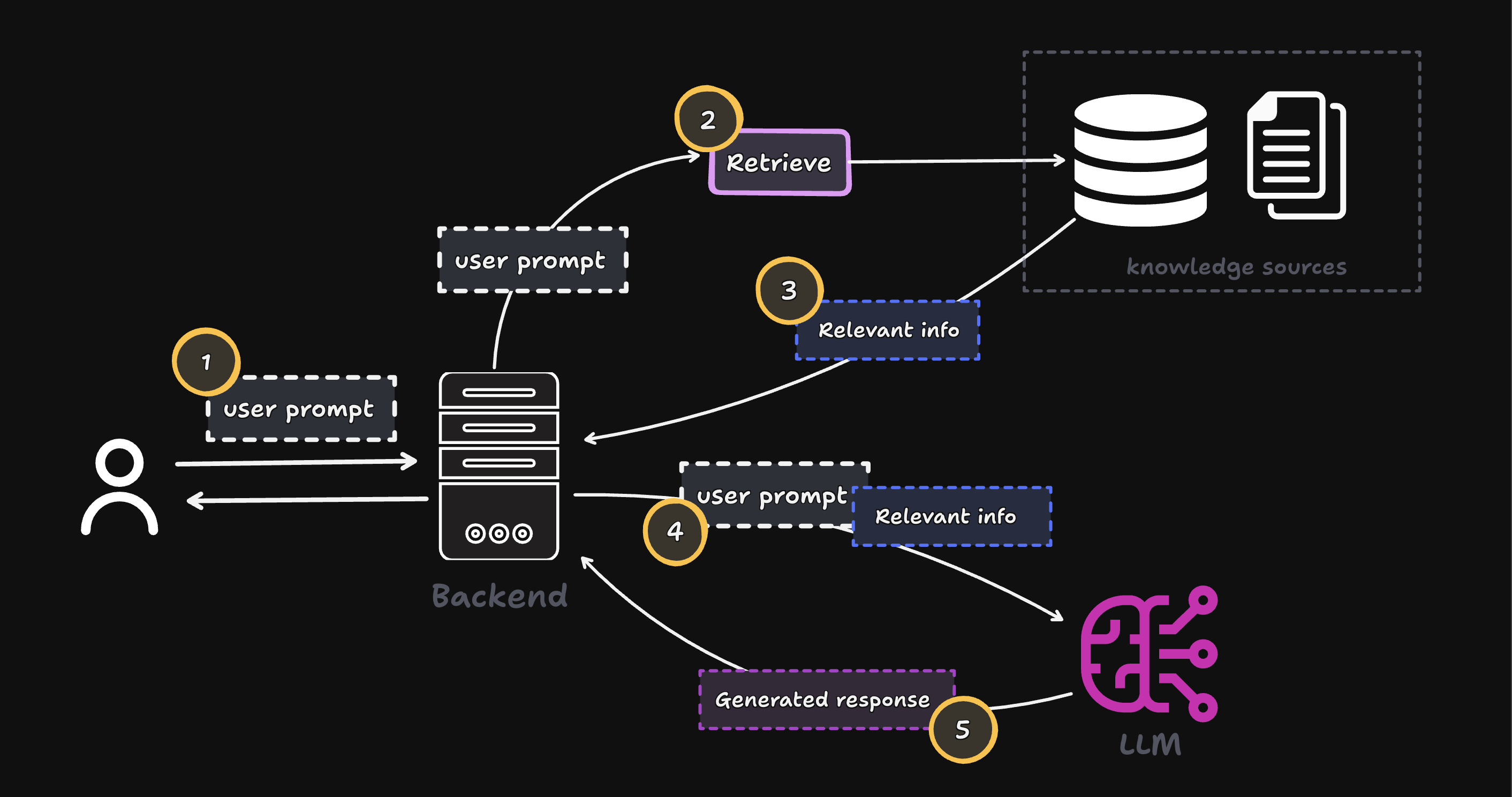
So the process becomes:
- User asks a question.
- Retrieve relevant information.
- Provide that information to the LLM.
- The LLM generates an accurate, context-aware answer.
That's why it's called Retrieval-Augmented Generation—we augment the generation process with retrieved knowledge.
Advantages of RAG
Let's summarize why RAG has become one of the most important techniques in Generative AI.

1. Access to Up-to-Date Information
RAG can retrieve the latest information from external sources.
This means your AI can answer questions about today's events, recent product launches, or newly published documents.
2. Works with Private Knowledge
RAG allows your AI to answer questions using:
- Company documents
- PDFs
- Confluence
- SharePoint
- Databases
- Knowledge bases
Without retraining the model.
3. Reduces Hallucinations
Since the model answers based on retrieved documents instead of pure memory, responses become much more accurate and trustworthy.
4. Easy to Update
Need to update your knowledge?
Simply add or modify the documents.
There's no need to retrain the LLM.
5. Cost Effective
Training or fine-tuning large language models can cost thousands or even millions of dollars.
RAG avoids this cost by keeping the model fixed and updating only the external knowledge base.
6. Builds user trust
One of the biggest advantages of RAG is transparency.
You can even show users the documents or passages that were used to generate the answer.
This builds trust because users can verify the information themselves.
Conclusion
To summarize:
A traditional LLM answers from memory.
A RAG system first retrieves relevant information and then generates the answer using that information.